Explaining Spectre and Meltdown
Introduction
Spectre and Meltdown are arguably the worst hardware security vulnerabilities present in modern day CPUs and between them, affect nearly every device produced in the last 20 years. Both vulnerabilities were discovered in 2018 and exploit the advanced features of modern CPUs to access data that is usually restricted. Meltdown was discovered by three teams: Jann Horn at Goole Project Zero, Warner Hass and Thomas Prescher at Cyberus Technology and Daniel Gruss, Moritz Lipp, Stefan Mangard and Michael Schwarz at Graz University of Technology [1]. Spectre was independently discovered by Jann Horn at Google Project Zero and Paul Kocher in collaboration with others [2]. Meltdown takes advantage of the microarchitecture side-effects resulting from out-of-order execution to enable an attacker to read memory locations allocated to other processes or reserved for kernel usage from a standard user space program. Spectre is similar and also takes advantage of microarchitecture side-effects but resulting from speculative execution.
Background
Virtual Memory and Memory Protection
Virtual memory is a memory management technique that abstracts the physical memory away from the program using the memory. Under this paradigm, every process running on a computer is given its own distinct (virtual) memory address space. The operating system (OS) manages the assignment of physical memory to virtual memory addresses, and a specialised unit within the CPU known as the Memory Management Unit (MMU) handles the translation of virtual addresses to physical addresses. This makes the job of the programmer easier as it will always appear to them as if they have a large block of contiguous memory available to them and they do not need to worry about other processes interfering with their usage of the memory.
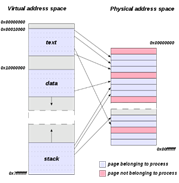
Both the physical and virtual memory are divided in fixed-length units called pages. Pages are typically 4096-bytes on modern CPU architectures. Virtual memory pages are mapped onto physical pages using an entry on a data structure called a page table. An entry in a page table will be indexed by first address in a virtual memory page and contain the corresponding first address in physical memory page (first column in figure 2) along with auxiliary information. The entry will then contain the translation information for virtual addresses in the range first address to first address + page size. The use of pages enables modern OSs to take advantage of a technique known as paging to provide more memory addresses then available memory by swapping pages to and from the backing storage as needed in order to free up room in the main memory.
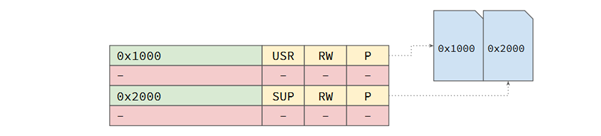
Modern OSs such as Linux typically create one page table per process. OSs need to protect unprivileged programs from accessing other program’s memory, and also need to prevent unprivileged programs accessing memory reserved by the operating system. They do this by dividing the memory into two access level: user space and kernel space. This memory protection is generally achieved by setting a bit in the page tables indicating whether a particular virtual memory page is in user or kernel space (column 2 in figure 2). The memory protection system may also provide read-only access in addition to read-write access and this would also be indicated by a bit in the page table (column 3 in figure 2). The page tables themselves are also protected using this technique.
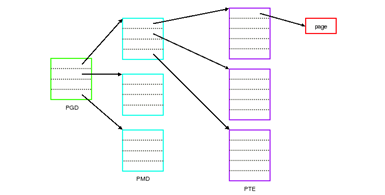
Some operating systems have separate page tables for kernel space addresses; however, most modern OSs store a reference to the kernel space page tables in each user space page table as an optimisation. This reduces the overheads associated with system calls as the kernel can quickly access its page tables. This can be achieved as page tables are generally hierarchical tree structures [3] as shown in figure 3.
Memory Caching
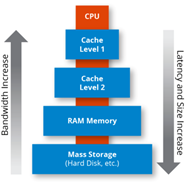
Memory operations are typically very slow in comparison to computation operations and faster memory technology is more expensive than slower technology. One technique that modern CPUs use in order to speed up slow memory operations is the use of memory caches. Memory caches are banks of high-speed memory chips that can store a subset of the data stored within main memory. Many modern CPUs have a number of caches organised into a hierarchy from fastest to slowest with main memory sitting below the lowest level cache. When the CPU attempts to fetch a memory address, it will first look in the highest-level cache. If it does not find the memory address, the next cache will be consulted. This continues until eventually the main memory is consulted. Naturally, the further down the hierarchy the CPU has to go in order to find the address it needs, the longer the memory operation will take to complete. If the desired address is not found in any of the caches, this is known as a cache miss, and the address is stored in the cache for future use. As a result, the most recently accessed addresses can be found in the cache.
Out-of-order Execution
One technique that modern CPUs utilise to improve performance is out-of-order execution which enables instruction level parallelism. Many of the instructions that a CPU is capable of executing take different amounts of time to complete and may utilise different parts of the CPU. As a result of this, it is often possible for a CPU to execute later instructions before prior instructions have completed. In order for this technique to be effective, the CPU must ensure all of the dependencies for a particular instruction are available before executing the instruction. This job is carried out by reservation stations. Each functional unit has a number of reservation station that can store instructions and operands for the operation and stall until all the operands are available. Once all the operands have been placed into the reservation station, the instruction can begin executing. Once an operation has completed, the result is available for other reservation stations waiting for it, however they are not written back (to memory or register) directly. Instead, they are placed in a special hardware buffer known as the reorder buffer. Results within the reorder buffer are then committedin order. If there is some sort of error such as an exception, the reorder buffer is flushed.
Speculative Execution
Speculative execution is another technique used enable instruction level parallelism. Control flow statements such as if statements and loops in high level languages, are translated into low level branch instructions. When a branch instruction is encountered, the CPU must either set the program counter (PC) to the target of the branch, or fall through the branch to the next sequential instruction depending on whether the branch is taken or not taken. However, it may take time to determine whether the branch is taken or not. Non-speculative CPUs simply stall until the outcome of the branch is known, but this wastes valuable cycles. Instead, speculative CPUs will predict the outcome of the branch and continue executing as if that prediction is correct. Any operations completed as a result of this prediction will be written to the reorder buffer and only committed once the outcome of the branch is known. If the prediction turns out to be incorrect, the reorder buffer will be flushed and execution will restart at the correct address. There are a number of strategies that can be used to predict branch outcomes, many of which take into account the outcome of previous branches.
Vulnerabilities
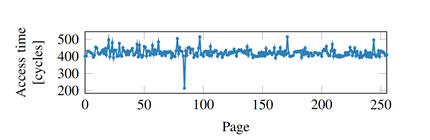
Both Meltdown and Spectre take advantage of the fact that it takes longer to load non-cached data then cached data. By using a high-resolution timer, it is possible to measure time taken to retrieve an address from memory. By performing experiments in a controlled environment, one can determine the amount of time it takes to retrieve a cached address vs a non-cached address on a particular CPU model.
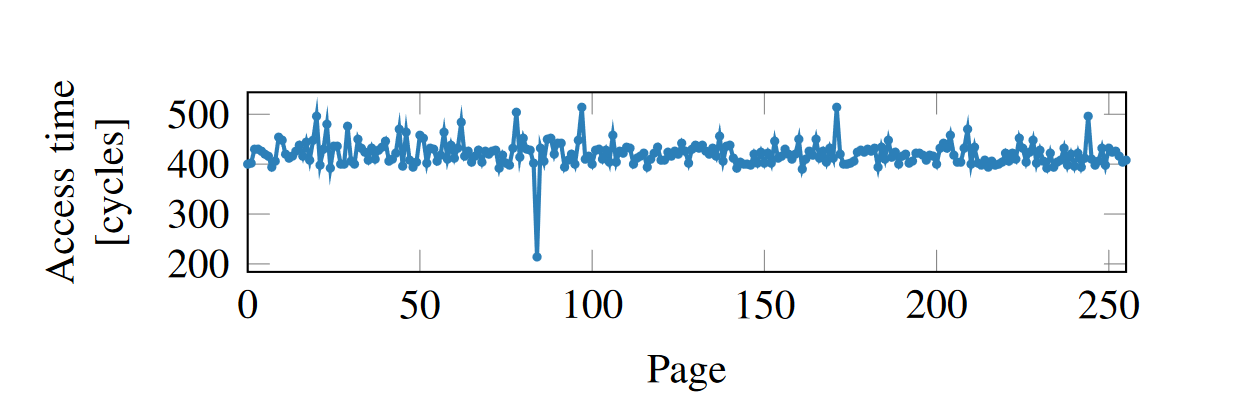
Exploiting this property is a type of side-channel attack on the CPU memory cache. In 2014, Yuval Yarom and Katrina Falkner proposed the Flush+Reload attack [7], where an attacker would flush a particular memory address from the cache and then reload it after a short time. If the reload occurs quicker then expected, then the attacker knows that another process has accessed that memory address since the flush. See figure 5 for a graphical illustration.
Meltdown
Description
Meltdown is an exploit that builds on the Flush+Reload attack and takes advantage of out-of-order execution to bypass memory protection and access restricted memory locations. The key insight of meltdown was the realisation that whilst uncommitted out-of-order execution does not affect the architectural state of the CPU, it can affect the microarchitectural state of the CPU, specifically, which memory addresses are cached.
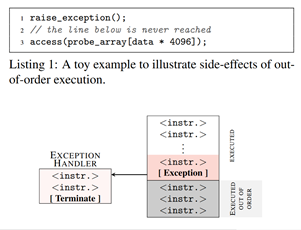
As discussed in the Out-of-order execution section above, if the CPU encounters an exception, any instructions that sequentially occurred after the instruction causing the exception should be discarded even if they have already been partially executed, and the CPUs architecture should be reset to the state it was in when the exception occurred. The instructions that are executed but never committed are referred to as transient instructions. However, there are no provisions to reset the cache into the state it was in before the transient instructions took place.
The meltdown paper proposes performing a Flush+Reload attack whilst simultaneously and deliberately introducing the side-effect. This is known as a covert side-channel attack. The following steps are taken assuming the cache line size is C:
1. Select accessible memory location A
2. Flush cache for memory locations A and A+log2(C)
3. Select restricted memory location R
4. Deliberately raise exception
5. Load R into Register X
6. Perform bit-wise AND on X such that 1 bit is isolated
7. Shift X by log2(C)
8. Load register y with A offset X
Once this has been done and the exception handler has finished executing, the times taken to access address A and address A+log2(C) are measured. If address A is in the cache, we know that the isolated bit was 0 and if A+log2(C) is in the cache, we know the isolated bit was 1. This can be continued for each bit in the restricted memory location until the entire value has been discovered.
For example, the value 0xffff is stored in a restricted memory location 0x1000. Restricted location 0x1000 is loaded into R0. Next an AND operation with mask 0x0001 will isolate the last bit of the value such that then new value in R0 is 0x0001. If the cache line size is 4, R0 is then shifted two places left (which is the same as multiplying by 4). Finally, the memory address at accessible location 0x2000 offset R0 is loaded. In this case the address loaded would be 0x2004 as the isolated bit is 1. However, if the value 0xfff0 was in memory location 0x1000, the address loaded would have been 0x2000. See figure 6 and 7 for diagrams illustrating this process.
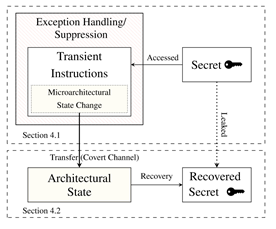
As discussed in the Virtual Memory and Memory Protection section, many OSs store references to the kernel space page tables in user space, and as a result the meltdown exploit can be used to access the information stored there. For many kernels, direct mappings to the entire physical memory are available in the kernel page tables and as a result meltdown can used to access any memory location on the system. The authors of the meltdown paper were able to access restricted data at a rate of between 3.2KB/s and 503KB/s depending on the platform.
Nearly every Intel CPU is vulnerable to the meltdown exploit [11]. Additionally, some ARM [12] and IBM [13] CPUs are also affected.
Mitigations
The meltdown vulnerability can be mitigated without requiring any hardware changes by fully separating the kernel and user spaces which is known as Kernel Page Table Isolation (KPTI). This can be done by removing the reference to the kernel page tables from each processes page tables and moving them to an entirely separate page table. Unfortunately, this massively increases overhead as the CPU needs to switch page tables every time a system call is made, and then switched back to the user page tables [8]. This overhead is particularly noticeable for programs that make a significant number of system calls. The popular SQL database Postgres for example reported a performance loss of between 7 – 17% with KPTI enabled [9].
Most OSs have now implemented a KPTI patch, however this will require users to update and restart their devices (which may be a challenge for always-on systems such as servers). This mitigation is in no way perfect as it has involved significantly degraded performance as the cost for security. Additionally, some researchers have suggested that KPTI does not fully solve the meltdown problem [10]. Better mitigations will only come about through improvements to the hardware.
Spectre
Description
Spectre is very similar to the meltdown exploit, it also builds upon the Flush+Reload attack, however it takes advantage of speculative execution rather then out-of-order execution. Spectre comes in two significant variants. The first variant is the bounds check bypass and this is shown in figure 8 [14].

In order to exploit the first variant of spectre, the body of the if statement must run even once the array is out of bounds. First, the branch predictor must be primed so that it will speculatively run the body of the if statement, even once x is larger then array1_size. To do this the if statement will need to be executed numerous times with x less then array1_size. Once the branch predictor is primed, the following scenario is engineered:
- The attacker is able to control the value of x
- array1_size is not cached
- array1 is cached
The attacker will select a desired secret value, k, which will first need to be loaded into the cache by making some sort of legitimate kernel call. Once this scenario is engineered, the attacker will select a value of x such that array1[x] dereferences to k. The body of the if statement will be speculatively executed whilst the CPU loads the value of array1_size (due to the primed prediction of the branch predictor). When the CPU loads array1[x] there will be a cache hit and k will be loaded. The program will proceed to loading array2[k * 256] which will involve loading some location of array2 into the cache. At this point the CPU will detect the misprediction and roll back the execution, but the side-effects on the cache will remain. The Flush+Reload attack can then be used to determine which array2 location is in cache and from this the value of k can be calculated [5].
The second variant of spectre is known as branch target injection. This is similar to the first variant but instead of aiming to get the CPU to speculatively execute an if statement, the attacker tries to trick the CPU into executing malicious code during an indirect branch. Indirect branches occur when the target of a branch cannot be known at compile time. For example, this could occur when a polymorphic class implements a virtual function in C++. At compile time, the compiler does not know which derived class’s implementation to use and may speculate on this. An attacker may be able to trick the CPU into executing a malicious function by priming the indirect branch predictor [15].
Spectre is more difficult to exploit then meltdown, however it also affects nearly every modern CPU that uses speculative execution.
Mitigations
There are no good mitigations for spectre available at the time of writing. Better mitigations will have to be implemented via hardware fixes. There have been mitigations proposed for both variants, but both effectively disable speculative execution for problematic areas.
The mitigation for variant 1 of spectre involves static analysis of the source code (and therefore recompilation of every program effected). During the statis analysis process, any critical areas that an attacker may be able to exploit using variant 1 of spectre are identified and an instruction that disables speculative execution (such as lfence) is placed just before the critical area. However, the disabling of speculative execution has significant performance ramifications and some doubt has been cast as to whether this is enough [16].
A mitigation for variant 2 called Retpoline has been proposed by Google [17]. This technique also effectively disables speculative execution for indirect branches by making the result of any speculative execution with regards to indirect branches result in an endless loop. The author of the paper provides this metaphor: “imagine speculative execution as an overly energetic 7-year-old that we must now build a warehouse of trampolines around”.
Consequences
The consequences of an unauthorised user having access to any restricted memory address is dramatic. Not only can running programs read and interfere with each other’s memory, but privileged kernel routines can be executed by unprivileged programs. This gives malicious programs the ability to steal sensitive data such as encryption keys and passwords as well as execute damaging functions such as formatting a drive. Even more worrying are the consequences for cloud server providers who frequently run multiple virtual machines on a single tenant – these individual machines are not as isolated as once thought and it is potentially possible for one VM to access another’s memory. Finally, all of the mitigations proposed for Spectre and Meltdown impose significant performance degradation. This results in less powerful machines and poorer value for money for consumers.
Impact
Meltdown affects a more limited set of CPUs then spectre and seems to have a simple hardware fix. AMD announced soon after the meltdown vulnerability was exposed that its CPUs were not vulnerable due to “privilege level protections within paging architecture” [18]. It is clear that Intel and other manufacturers affected by the meltdown vulnerability need to implement similar measures. However, OS designers may also want to consider whether it makes sense to store references to kernel space in user space. A possible solution may be hardware level support for rapid switching between page tables.
The spectre vulnerability still does not have a good hardware level fix, and hardware designers will need to propose safer methods of speculative execution that avoid the dangers outlined by the spectre exploit. Hopefully, these can be achieved without effectively disabling the speculative execution around the problematic areas and without requiring static analysis of source code.
Both meltdown and spectre exploit the behaviour of memory caches with regards to transient instructions. One possibility that would put a stop to both vulnerabilities would be to find a way to roll back the cache-state along with the rest of the architecture when an exception or misprediction is detected. However, this would likely invoke significant overhead and it would be a challenge to find an efficient mechanism to implement this.
Conclusion
Both meltdown and spectre are serious security bugs that have still not been solved. Even once new CPUs are able to find fixes for these vulnerabilities, there will still be countless devices operating with old CPUs that will remain vulnerable. Hardware designers have a lot to learn from these vulnerabilities and may need to be more rigorous in their security testing before releasing new technologies in the future. That said, too much caution from hardware designers could stifle innovation.
References
|
[1] |
Moritz Lipp
et al, 2018: “Meltdown: Reading Kernel Memory from User Space” |
|
[2] |
Paul Kocher
et al, 2018: “Spectre Attacks: Exploiting speculative execution” |
|
[3] |
Corbet, 2004:
“Four-level page tables”; https://lwn.net/Articles/106177/
accessed 28/03/2022 |
|
[4] |
Wikipedia:
“Page Table”; https://en.wikipedia.org/wiki/Page_table
accessed on 28/03/2022 |
|
[5] |
Tom Spink,
2022: “CS4202 Lecture 9: Hardware Security” |
|
[6] |
Hazelcast: “Memory
Caching”; https://hazelcast.com/glossary/memory-caching/
accessed on 28/03/2022 |
|
[7] |
Yuval Yarom
& Katrina Falkner, 2014: “Flush+Reload: A High Resolution, Low Noise, L3 Cache
Side-Channel Attack” |
|
[8] |
Lars Müller
2018: “KPTI a Mitigation Method against Meltdown”, WASOM 18 |
|
[9] |
Andres Freund
2018: “heads up: Fix for intel hardware bug will lead to performance
regressions”; https://www.postgresql.org/message-id/20180102222354.qikjmf7dvnjgbkxe%40alap3.anarazel.de
accessed on 29/03/2022 |
|
[10] |
Cheng et al.
2021: “Meltdown-type attacks are still feasible in the wall of kernel
page-Table isolation” |
|
[11] |
Intel: “Affected
Processors: Transient Execution Attacks & Related Security Issues by CPU”;
https://www.intel.com/content/www/us/en/developer/topic-technology/software-security-guidance/processors-affected-consolidated-product-cpu-model.html
accessed on 29/03/2022 |
|
[12] |
ARM 2022: “Vulnerability
of Speculative Processors to Cache Timing Side-Channel Mechanism”; https://developer.arm.com/support/arm-security-updates/speculative-processor-vulnerability
accessed on 29/03/2022 |
|
[13] |
IBM 2019: “Potential
Impact on Processors in the POWER Family”: https://www.ibm.com/blogs/psirt/potential-impact-processors-power-family/
accessed 29/03/2022 |
|
[14] |
Matt Klein,
2018: “Meltdown and Spectre, explained”; https://medium.com/@mattklein123/meltdown-spectre-explained-6bc8634cc0c2
accessed 29/03/2022 |
|
[15] |
Wikichip:
“CVE-2017-5715 (Spectre, Variant 2) – CVE”; https://en.wikichip.org/wiki/cve/cve-2017-5715
accessed on 29/03/2022 |
|
[16] |
AMD, 2022:
“LFENCE/JMP Mitigation Update for CVE-2017-5715”; https://www.amd.com/en/corporate/product-security/bulletin/amd-sb-1036
accessed on 29/03/2022 |
|
[17] |
Paul Turner,
2018: “Retpoline: a software construct for preventing branch-target-injection” |
|
[18] |
AMD 2018: “An
Update on AMD Processor Security”; https://www.amd.com/en/corporate/speculative-execution-previous-updates
accessed on 23/03/2022 |